Inspect
An open-source framework for large language model evaluations
Welcome
Welcome to Inspect, a framework for large language model evaluations created by the UK AI Security Institute.
Inspect provides many built-in components, including facilities for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Extensions to Inspect (e.g. to support new elicitation and scoring techniques) can be provided by other Python packages.
We’ll walk through a fairly trivial “Hello, Inspect” example below. Read on to learn the basics, then read the documentation on Options, Solvers, Tools, Scorers, Datasets, and Models to learn how to create more advanced evaluations.
Getting Started
To get started using Inspect:
Install Inspect from PyPI with:
pip install inspect-aiIf you are using VS Code, install the Inspect VS Code Extension (not required but highly recommended).
To develop and run evaluations, you’ll also need access to a model, which typically requires installation of a Python package as well as ensuring that the appropriate API key is available in the environment.
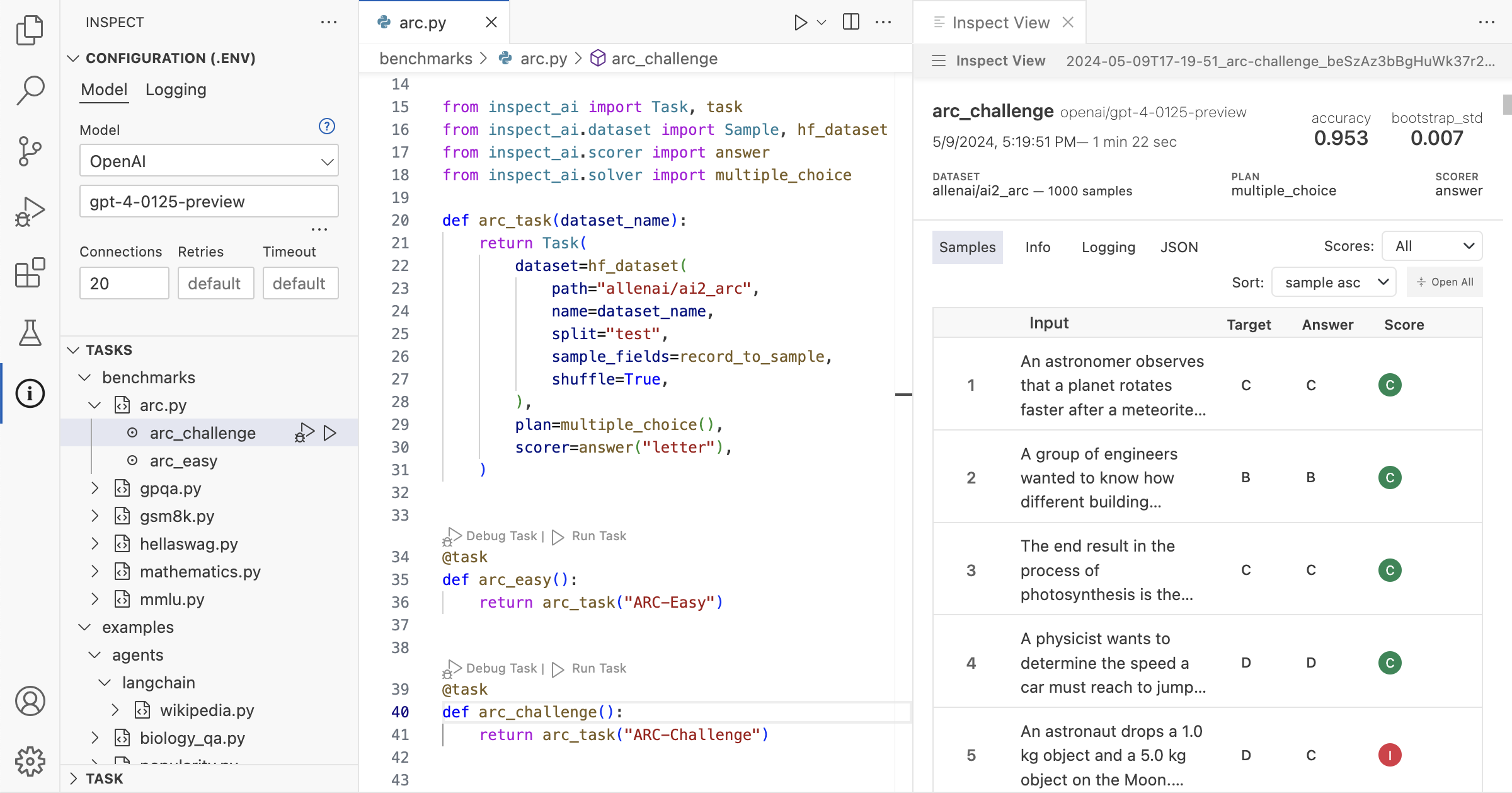
Assuming you had written an evaluation in a script named arc.py, here’s how you would setup and run the eval for a few different model providers:
pip install openai
export OPENAI_API_KEY=your-openai-api-key
inspect eval arc.py --model openai/gpt-4opip install anthropic
export ANTHROPIC_API_KEY=your-anthropic-api-key
inspect eval arc.py --model anthropic/claude-3-5-sonnet-latestpip install google-genai
export GOOGLE_API_KEY=your-google-api-key
inspect eval arc.py --model google/gemini-1.5-propip install openai
export GROK_API_KEY=your-grok-api-key
inspect eval arc.py --model grok/grok-betapip install mistralai
export MISTRAL_API_KEY=your-mistral-api-key
inspect eval arc.py --model mistral/mistral-large-latestpip install torch transformers
export HF_TOKEN=your-hf-token
inspect eval arc.py --model hf/meta-llama/Llama-2-7b-chat-hfIn addition to the model providers shown above, Inspect also supports models hosted on AWS Bedrock, Azure AI, Vertex AI, TogetherAI, Groq, Cloudflare, and Goodfire as well as local models with vLLM, Ollama or llama-cpp-python.
Hello, Inspect
Inspect evaluations have three main components:
Datasets contain a set of labelled samples. Datasets are typically just a table with
inputandtargetcolumns, whereinputis a prompt andtargetis either literal value(s) or grading guidance.Solvers are chained together to evaluate the
inputin the dataset and produce a final result. The most elemental solver, generate(), just calls the model with a prompt and collects the output. Other solvers might do prompt engineering, multi-turn dialog, critique, or provide an agent scaffold.Scorers evaluate the final output of solvers. They may use text comparisons, model grading, or other custom schemes
Let’s take a look at a simple evaluation that aims to see how models perform on the Sally-Anne test, which assesses the ability of a person to infer false beliefs in others. Here are some samples from the dataset:
| input | target |
|---|---|
| Jackson entered the hall. Chloe entered the hall. The boots is in the bathtub. Jackson exited the hall. Jackson entered the dining_room. Chloe moved the boots to the pantry. Where was the boots at the beginning? | bathtub |
| Hannah entered the patio. Noah entered the patio. The sweater is in the bucket. Noah exited the patio. Ethan entered the study. Ethan exited the study. Hannah moved the sweater to the pantry. Where will Hannah look for the sweater? | pantry |
Here’s the code for the evaluation (click on the numbers at right for further explanation):
theory.py
from inspect_ai import Task, task
from inspect_ai.dataset import example_dataset
from inspect_ai.scorer import model_graded_fact
from inspect_ai.solver import (
chain_of_thought, generate, self_critique
)
@task
def theory_of_mind():
return Task(
dataset=example_dataset("theory_of_mind"),
solver=[
chain_of_thought(),
generate(),
self_critique()
],
scorer=model_graded_fact()
)- 1
- The Task object brings together the dataset, solvers, and scorer, and is then evaluated using a model.
- 2
- In this example we are chaining together three standard solver components. It’s also possible to create a more complex custom solver that manages state and interactions internally.
- 3
- Since the output is likely to have pretty involved language, we use a model for scoring.
Note that you can provide a single solver or multiple solvers chained together as we did here.
The @task decorator applied to the theory_of_mind() function is what enables inspect eval to find and run the eval in the source file passed to it. For example, here we run the eval against GPT-4:
inspect eval theory.py --model openai/gpt-4
Evaluation Logs
By default, eval logs are written to the ./logs sub-directory of the current working directory. When the eval is complete you will find a link to the log at the bottom of the task results summary.
If you are using VS Code, we recommend installing the Inspect VS Code Extension and using its integrated log browsing and viewing.
For other editors, you can use the inspect view command to open a log viewer in the browser (you only need to do this once as the viewer will automatically updated when new evals are run):
inspect view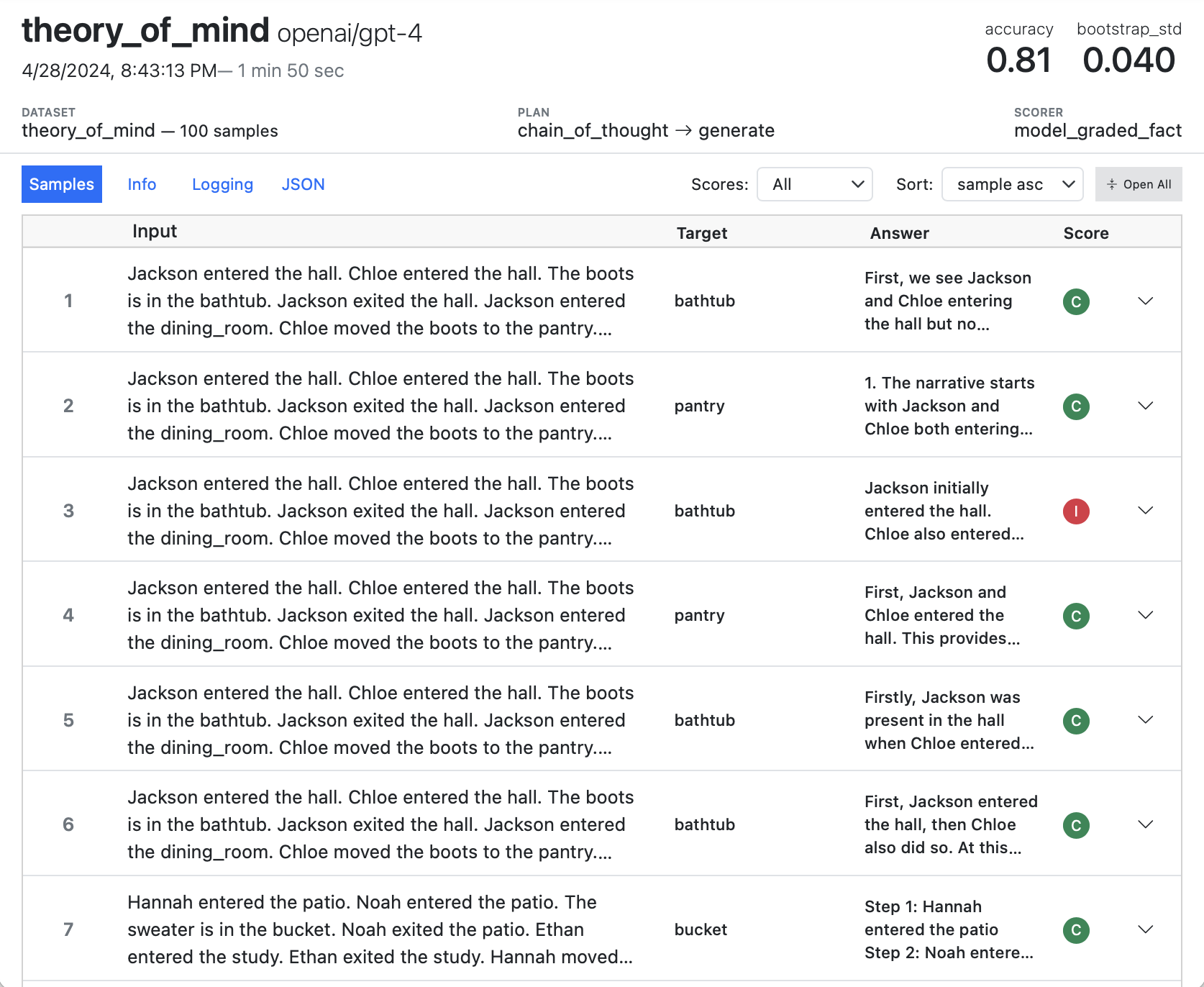
See the Log Viewer section for additional details on using Inspect View.
Eval from Python
Above we demonstrated using inspect eval from CLI to run evaluations—you can perform all of the same operations from directly within Python using the eval() function. For example:
from inspect_ai import eval
eval(theory_of_mind(), model="openai/gpt-4o")Learning More
The best way to get familar with Inspect’s core features is the Tutorial, which includes several annotated examples.
Next, review these articles which cover basic workflow, more sophisticated examples, and additional useful tooling:
Options covers the various options available for evaluations as well as how to manage model credentials.
Evals are a set of ready to run evaluations that implement popular LLM benchmarks and papers.
Log Viewer goes into more depth on how to use Inspect View to develop and debug evaluations, including how to provide additional log metadata and how to integrate it with Python’s standard logging module.
VS Code provides documentation on using the Inspect VS Code Extension to run, tune, debug, and visualise evaluations.
These sections provide a more in depth treatment of the various components used in evals. Read them as required as you learn to build evaluations.
Tasks bring together datasets, solvers, and scorers to define a evaluation. This section explores strategies for creating flexible and re-usable tasks.
Datasets provide samples to evaluation tasks. This section illustrates how to adapt various data sources for use with Inspect, as well as how to include multi-modal data (images, etc.) in your datasets.
Solvers are the heart of Inspect, and encompass prompt engineering and various other elicitation strategies (the
planin the example above). Here we cover using the built-in solvers and creating your own more sophisticated ones.Scorers evaluate the work of solvers and aggregate scores into metrics. Sophisticated evals often require custom scorers that use models to evaluate output. This section covers how to create them.
These sections cover defining custom tools as well as Inspect’s standard built-in tools:
Tool Basics: Tools provide a means of extending the capabilities of models by registering Python functions for them to call. This section describes how to create custom tools and use them in evaluations.
Custom Tools provides details on more advanced custom tool features including sandboxing, error handling, and dynamic tool definitions.
Standard Tools describes Inspect’s built-in tools for code execution, text editing, computer use, web search, and web browsing.
These sections cover how to use various language models with Inspect:
Models describe various ways to specify and provide options to models in Inspect evaluations.
Providers covers usage details and available options for the various supported providers.
Caching explains how to cache model output to reduce the number of API calls made.
Multimodal describes the APIs available for creating multimodal evaluations (including images, audio, and video).
Reasoning documents the additional options and data available for reasoning models.
Structured Output explains how to constrain model output to a particular JSON schema.
These sections describe how to create agent evaluations with Inspect:
Agents combine planning, memory, and tool usage to pursue more complex, longer horizon tasks. This articles covers the basics of agent evaluations.
Sandboxing enables you to isolate code generated by models as well as set up more complex computing environments for tasks.
Agent API describes advanced Inspect APIs available for creating evaluations with agents.
Agent Bridge enables the use of agents from 3rd party frameworks like AutoGen or LangChain with Inspect.
Human Agent is a solver that enables human baselining on computing tasks.
Approval enable you to create fine-grained policies for approving tool calls made by model agents.
These sections discuss more advanced features and workflows. You don’t need to review them at the outset, but be sure to revisit them as you get more comfortable with the basics.
Eval Logs explores how to get the most out of evaluation logs for developing, debugging, and analyzing evaluations.
Eval Sets covers Inspect’s features for describing, running, and analysing larger sets of evaluation tasks.
Errors and Limits covers various techniques for dealing with unexpected errors and setting limits on evaluation tasks and samples.
Multimodal documents the APIs available for creating multimodal evaluations (including images, audio, and video).
Typing: provides guidance on using static type checking with Inspect, including creating typed interfaces to untyped storage (i.e. sample metadata and store).
Tracing Describes advanced execution tracing tools used to diagnose runtime issues.
Caching enables you to cache model output to reduce the number of API calls made, saving both time and expense.
Parallelism delves into how to obtain maximum performance for evaluations. Inspect uses a highly parallel async architecture—here we cover how to tune this parallelism (e.g to stay under API rate limits or to not overburden local compute) for optimal throughput.
Interactivity covers various ways to introduce user interaction into the implementation of tasks (for example, prompting the model dynamically based on the trajectory of the evaluation).
Extensions describes the various ways you can extend Inspect, including adding support for new Model APIs, tool execution environments, and storage platforms (for datasets, prompts, and logs).
Citation
@software{UK_AI_Security_Institute_Inspect_AI_Framework_2024,
author = {AI Security Institute, UK},
title = {Inspect {AI:} {Framework} for {Large} {Language} {Model}
{Evaluations}},
date = {2024-05},
url = {https://github.com/UKGovernmentBEIS/inspect_ai},
langid = {en}
}