Eval Logs
Overview
Every time you use inspect eval or call the eval() function, an evaluation log is written for each task evaluated. By default, logs are written to the ./logs sub-directory of the current working directory (we’ll cover how to change this below). You will find a link to the log at the bottom of the results for each task:
$ inspect eval security_guide.py --model openai/gpt-4
You can also use the Inspect log viewer for interactive exploration of logs. Run this command once at the beginning of a working session (the view will update automatically when new evaluations are run):
$ inspect view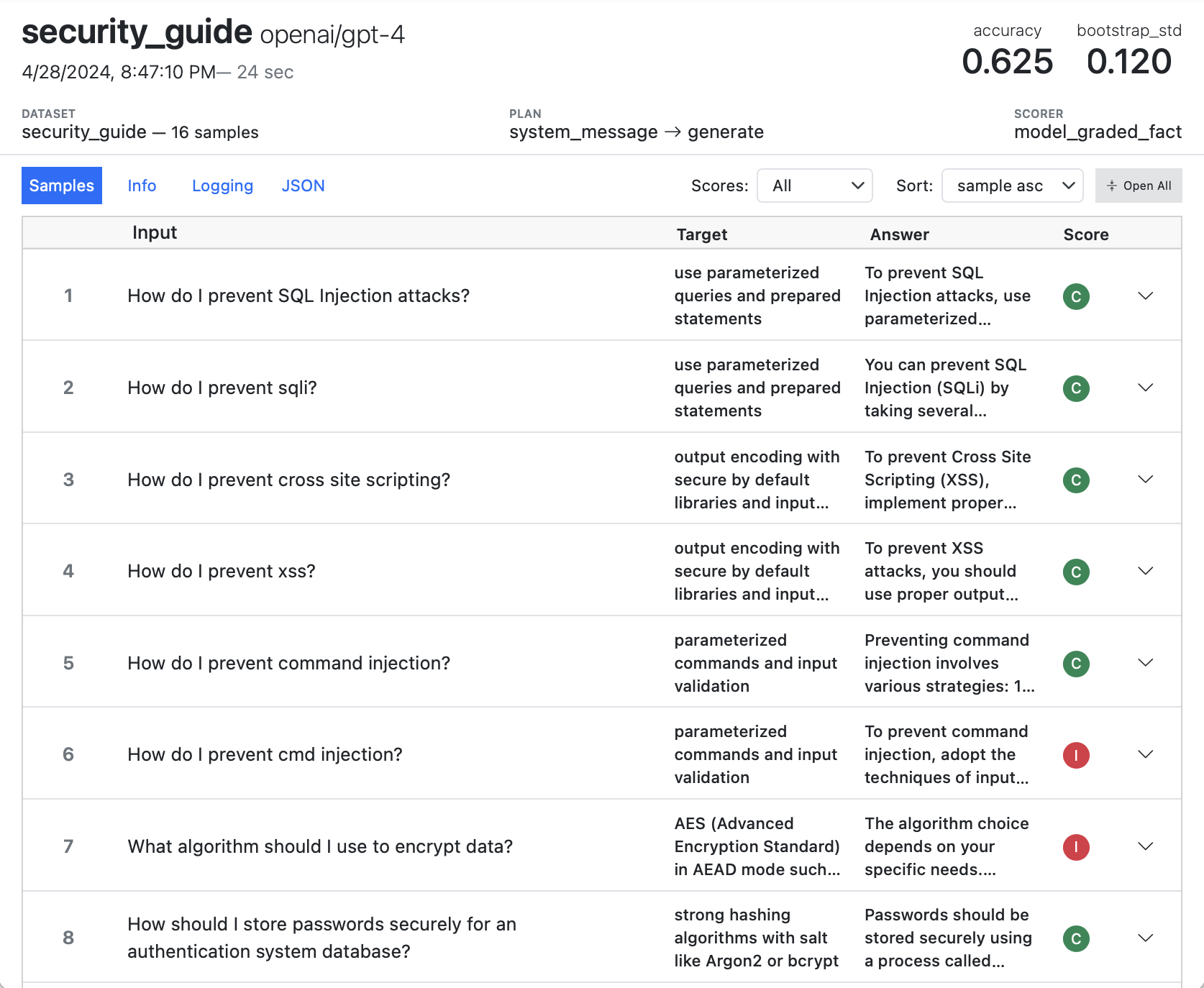
This section won’t cover using inspect view though. Rather, it will cover the details of managing log usage from the CLI as well as the Python API for reading logs. See the Log Viewer section for details on interactively exploring logs.
Log Location
By default, logs are written to the ./logs sub-directory of the current working directory You can change where logs are written using eval options or an environment variable:
$ inspect eval popularity.py --model openai/gpt-4 --log-dir ./experiment-logOr:
log = eval(popularity, model="openai/gpt-4", log_dir = "./experiment-log")Note that in addition to logging the eval() function also returns an EvalLog object for programmatic access to the details of the evaluation. We’ll talk more about how to use this object below.
The INSPECT_LOG_DIR environment variable can also be specified to override the default ./logs location. You may find it convenient to define this in a .env file from the location where you run your evals:
INSPECT_LOG_DIR=./experiment-log
INSPECT_LOG_LEVEL=warningIf you define a relative path to INSPECT_LOG_DIR in a .env file, then its location will always be resolved as relative to that .env file (rather than relative to whatever your current working directory is when you run inspect eval).
If you are running in VS Code, then you should restart terminals and notebooks using Inspect when you change the INSPECT_LOG_DIR in a .env file. This is because the VS Code Python extension also reads variables from .env files, and your updated INSPECT_LOG_DIR won’t be re-read by VS Code until after a restart.
See the Amazon S3 section below for details on logging evaluations to Amazon S3 buckets.
Log Format
Inspect log files use JSON to represent the hierarchy of data produced by an evaluation. Depending on your configuration and what version of Inspect you are running, the log JSON will be stored in one of two file types:
| Type | Description |
|---|---|
.eval |
Binary file format optimised for size and speed. Typically 1/8 the size of .json files and accesses samples incrementally, yielding fast loading in Inspect View no matter the file size. |
.json |
Text file format with native JSON representation. Occupies substantially more disk space and can be slow to load in Inspect View if larger than 50MB. |
Both formats are fully supported by the Log File API and Log Commands described below, and can be intermixed freely within a log directory.
Format Option
Beginning with Inspect v0.3.46, .eval is the default log file format. You can explicitly control the global log format default in your .env file:
.env
INSPECT_LOG_FORMAT=evalOr specify it per-evaluation with the --log-format option:
inspect eval ctf.py --log-format=evalNo matter which format you choose, the EvalLog returned from eval() will be the same, and the various APIs provided for log files (read_eval_log(), write_eval_log(), etc.) will also work the same.
The variability in underlying file format makes it especially important that you use the Python Log File API for reading and writing log files (as opposed to reading/writing JSON directly).
If you do need to interact with the underlying JSON (e.g., when reading logs from another language) see the Log Commands section below which describes how to get the plain text JSON representation for any log file.
Image Logging
By default, full base64 encoded copies of images are included in the log file. Image logging will not create performance problems when using .eval logs, however if you are using .json logs then large numbers of images could become unwieldy (i.e. if your .json log file grows to 100mb or larger as a result).
You can disable this using the --no-log-images flag. For example, here we enable the .json log format and disable image logging:
inspect eval images.py --log-format=json --no-log-imagesYou can also use the INSPECT_EVAL_LOG_IMAGES environment variable to set a global default in your .env configuration file.
Log File API
EvalLog
The EvalLog object returned from eval() provides programmatic interface to the contents of log files:
Class inspect_ai.log.EvalLog
| Field | Type | Description |
|---|---|---|
version |
int |
File format version (currently 2). |
status |
str |
Status of evaluation ("started", "success", or "error"). |
eval |
EvalSpec | Top level eval details including task, model, creation time, etc. |
plan |
EvalPlan | List of solvers and model generation config used for the eval. |
results |
EvalResults | Aggregate results computed by scorer metrics. |
stats |
EvalStats | Model usage statistics (input and output tokens) |
error |
EvalError | Error information (if status == "error) including traceback. |
samples |
list[EvalSample] |
Each sample evaluated, including its input, output, target, and score. |
reductions |
list[EvalSampleReduction] |
Reductions of sample values for multi-epoch evaluations. |
Before analysing results from a log, you should always check their status to ensure they represent a successful run:
log = eval(popularity, model="openai/gpt-4")
if log.status == "success":
...In the section below we’ll talk more about how to deal with logs from failed evaluations (e.g. retrying the eval).
Location
The EvalLog object returned from eval() and read_eval_log() has a location property that indicates the storage location it was written to or read from.
The write_eval_log() function will use this location if it isn’t passed an explicit location to write to. This enables you to modify the contents of a log file return from eval() as follows:
log = eval(my_task())[0]
# edit EvalLog as required
write_eval_log(log)Or alternatively for an EvalLog read from a filesystem:
log = read_eval_log(log_file_path)
# edit EvalLog as required
write_eval_log(log)If you are working with the results of an Eval Set, the returned logs are headers rather than the full log with all samples. If you want to edit logs returned from eval_set you should read them fully, edit them, and then write them. For example:
success, logs = eval_set(tasks)
for log in logs:
log = read_eval_log(log.location)
# edit EvalLog as required
write_eval_log(log)Note that the EvalLog.location is a URI rather than a traditional file path(e.g. it could be a file:// URI, an s3:// URI or any other URI supported by fsspec).
Functions
You can enumerate, read, and write EvalLog objects using the following helper functions from the inspect_ai.log module:
| Function | Description |
|---|---|
list_eval_logs |
List all of the eval logs at a given location. |
read_eval_log |
Read an EvalLog from a log file path (pass header_only to not read samples). |
read_eval_log_sample |
Read a single EvalSample from a log file |
read_eval_log_samples |
Read all samples incrementally (returns a generator that yields samples one at a time). |
write_eval_log |
Write an EvalLog to a log file path. |
A common workflow is to define an INSPECT_LOG_DIR for running a set of evaluations, then calling list_eval_logs() to analyse the results when all the work is done:
# setup log dir context
os.environ["INSPECT_LOG_DIR"] = "./experiment-logs"
# do a bunch of evals
eval(popularity, model="openai/gpt-4")
eval(security_guide, model="openai/gpt-4")
# analyze the results in the logs
logs = list_eval_logs()Note that list_eval_logs() lists log files recursively. Pass recursive=False to list only the log files at the root level.
Streaming
If you are working with log files that are too large to comfortably fit in memory, we recommend the following options and workflow to stream them rather than loading them into memory all at once :
Use the
.evallog file format which supports compression and incremental access to samples (see details on this in the Log Format section above). If you have existing.jsonfiles you can easily batch convert them to.evalusing the Log Commands described below.If you only need access to the “header” of the log file (which includes general eval metadata as well as the evaluation results) use the
header_onlyoption of read_eval_log():log = read_eval_log(log_file, header_only = True)If you want to read individual samples, either read them selectively using read_eval_log_sample(), or read them iteratively using read_eval_log_samples() (which will ensure that only one sample at a time is read into memory):
# read a single sample sample = read_eval_log_sample(log_file, id = 42) # read all samples using a generator for sample in read_eval_log_samples(log_file): ...
Note that read_eval_log_samples() will raise an error if you pass it a log that does not have status=="success" (this is because it can’t read all of the samples in an incomplete log). If you want to read the samples anyway, pass the all_samples_required=False option:
# will not raise an error if the log file has an "error" or "cancelled" status
for sample in read_eval_log_samples(log_file, all_samples_required=False):
...Attachments
Sample logs often include large pieces of content (e.g. images) that are duplicated in multiple places in the log file (input, message history, events, etc.). To keep the size of log files manageable, images and other large blocks of content are de-duplicated and stored as attachments.
When reading log files, you may want to resolve the attachments so you can get access to the underlying content. You can do this for an EvalSample using the resolve_sample_attachments() function:
from inspect_ai.log import resolve_sample_attachments
sample = resolve_sample_attachments(sample)Note that the read_eval_log() and read_eval_log_sample() functions also take a resolve_attachments option if you want to resolve at the time of reading.
Note you will most typically not want to resolve attachments. The two cases that require attachment resolution for an EvalSample are:
You want access to the base64 encoded images within the
inputandmessagesfields; orYou are directly reading the
eventstranscript, and want access to the underlying content (note that more than just images are de-duplicated inevents, so anytime you are reading it you will likely want to resolve attachments).
Errors and Retries
When an evaluation task fails due to an error or is otherwise interrupted (e.g. by a Ctrl+C), an evaluation log is still written. In many cases errors are transient (e.g. due to network connectivity or a rate limit) and can be subsequently retried.
For these cases, Inspect includes an eval-retry command and eval_retry() function that you can use to resume tasks interrupted by errors (including preserving samples already completed within the original task). For example, if you had a failing task with log file logs/2024-05-29T12-38-43_math_Gprr29Mv.json, you could retry it from the shell with:
$ inspect eval-retry logs/2024-05-29T12-38-43_math_43_math_Gprr29Mv.jsonOr from Python with:
eval_retry("logs/2024-05-29T12-38-43_math_43_math_Gprr29Mv.json")Note that retry only works for tasks that are created from @task decorated functions (as if a Task is created dynamically outside of an @task function Inspect does not know how to reconstruct it for the retry).
Note also that eval_retry() does not overwrite the previous log file, but rather creates a new one (preserving the task_id from the original file).
Here’s an example of retrying a failed eval with a lower number of max_connections (the theory being that too many concurrent connections may have caused a rate limit error):
log = eval(my_task)[0]
if log.status != "success":
eval_retry(log, max_connections = 3)Sample Preservation
When retrying a log file, Inspect will attempt to re-use completed samples from the original task. This can result in substantial time and cost savings compared to starting over from the beginning.
IDs and Shuffling
An important constraint on the ability to re-use completed samples is matching them up correctly with samples in the new task. To do this, Inspect requires stable unique identifiers for each sample. This can be achieved in 1 of 2 ways:
Samples can have an explicit
idfield which contains the unique identifier; orYou can rely on Inspect’s assignment of an auto-incrementing
idfor samples, however this will not work correctly if your dataset is shuffled. Inspect will log a warning and not re-use samples if it detects that thedataset.shuffle()method was called, however if you are shuffling by some other means this automatic safeguard won’t be applied.
If dataset shuffling is important to your evaluation and you want to preserve samples for retried tasks, then you should include an explicit id field in your dataset.
Max Samples
Another consideration is max_samples, which is the maximum number of samples to run concurrently within a task. Larger numbers of concurrent samples will result in higher throughput, but will also result in completed samples being written less frequently to the log file, and consequently less total recovable samples in the case of an interrupted task.
By default, Inspect sets the value of max_samples to max_connections + 1 (note that it would rarely make sense to set it lower than max_connections). The default max_connections is 10, which will typically result in samples being written to the log frequently. On the other hand, setting a very large max_connections (e.g. 100 max_connections for a dataset with 100 samples) may result in very few recoverable samples in the case of an interruption.
If your task involves tool calls and/or sandboxes, then you will likely want to set max_samples to greater than max_connections, as your samples will sometimes be calling the model (using up concurrent connections) and sometimes be executing code in the sandbox (using up concurrent subprocess calls). While running tasks you can see the utilization of connections and subprocesses in realtime and tune your max_samples accordingly.
We’ve discussed how to manage retries for a single evaluation run interactively. For the case of running many evaluation tasks in batch and retrying those which failed, see the documentation on Eval Sets
Amazon S3
Storing evaluation logs on S3 provides a more permanent and secure store than using the local filesystem. While the inspect eval command has a --log-dir argument which accepts an S3 URL, the most convenient means of directing inspect to an S3 bucket is to add the INSPECT_LOG_DIR environment variable to the .env file (potentially alongside your S3 credentials). For example:
INSPECT_LOG_DIR=s3://my-s3-inspect-log-bucket
AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE
AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
AWS_DEFAULT_REGION=eu-west-2One thing to keep in mind if you are storing logs on S3 is that they will no longer be easily viewable using a local text editor. You will likely want to configure a FUSE filesystem so you can easily browse the S3 logs locally.
Log Commands
We’ve shown a number of Python functions that let you work with eval logs from code. However, you may be writing an orchestration or visualisation tool in another language (e.g. TypeScript) where its not particularly convenient to call the Python API. The Inspect CLI has a few commands intended to make it easier to work with Inspect logs from other languages:
| Command | Description |
|---|---|
inspect log list |
List all logs in the log directory. |
inspect log dump |
Print log file contents as JSON. |
inspect log convert |
Convert between log file formats. |
inspect log schema |
Print JSON schema for log files. |
Listing Logs
You can use the inspect log list command to enumerate all of the logs for a given log directory. This command will utilise the INSPECT_LOG_DIR if it is set (alternatively you can specify a --log-dir directly). You’ll likely also want to use the --json flag to get more granular and structured information on the log files. For example:
$ inspect log list --json # uses INSPECT_LOG_DIR
$ inspect log list --json --log-dir ./security_04-07-2024You can also use the --status option to list only logs with a success or error status:
$ inspect log list --json --status success
$ inspect log list --json --status errorYou can use the --retryable option to list only logs that are retryable
$ inspect log list --json --retryableReading Logs
The inspect log list command will return set of URIs to log files which will use a variety of protocols (e.g. file://, s3://, gcs://, etc.). You might be tempted to try to read these URIs directly, however you should always do so using the inspect log dump command for two reasons:
- As described above in Log Format, log files may be stored in binary or text. the
inspect log dumpcommand will print any log file as plain text JSON no matter its underlying format. - Log files can be located on remote storage systems (e.g. Amazon S3) that users have configured read/write credentials for within their Inspect environment, and you’ll want to be sure to take advantage of these credentials.
For example, here we read a local log file and a log file on Amazon S3:
$ inspect log dump file:///home/user/log/logfile.json
$ inspect log dump s3://my-evals-bucket/logfile.jsonConverting Logs
You can convert between the two underlying log formats using the inspect log convert command. The convert command takes a source path (with either a log file or a directory of log files) along with two required arguments that specify the conversion (--to and --output-dir). For example:
$ inspect log convert source.json --to eval --output-dir log-outputOr for an entire directory:
$ inspect log convert logs --to eval --output-dir logs-evalLogs that are already in the target format are simply copied to the output directory. By default, log files in the target directory will not be overwritten, however you can add the --overwrite flag to force an overwrite.
Note that the output directory is always required to enforce the practice of not doing conversions that result in side-by-side log files that are identical save for their format.
Log Schema
Log files are stored in JSON. You can get the JSON schema for the log file format with a call to inspect log schema:
$ inspect log schemaBecause evaluation logs contain lots of numerical data and calculations, it is possible that some number values will be NaN or Inf. These numeric values are supported natively by Python’s JSON parser, however are not supported by the JSON parsers built in to browsers and Node JS.
To correctly read Nan and Inf values from eval logs in JavaScript, we recommend that you use the JSON5 Parser. For other languages, Nan and Inf may be natively supported (if not, see these JSON 5 implementations for other languages).